注意力机制与Transformer架构
省流¶
### 注意力机制
**作用**:注意力机制是一种模拟人类注意力的技术,它允许模型在处理信息时能够聚焦于与当前任务最相关的部分,从而提高处理效率和准确性。
**能干什么**:通过计算输入序列中每个元素与其他元素的相关性,为它们分配不同的权重,使模型能够更好地捕捉序列中的关联信息和长距离依赖关系。
**一般拿来分析的问题**:
- **自然语言处理**:如机器翻译、文本摘要、问答系统等,帮助模型关注源语言中的关键信息。
- **计算机视觉**:在图像识别、目标检测等任务中,聚焦于图像中的关键区域。
- **语音处理**:在语音识别和合成中,捕捉语音信号中的重要特征。
- **推荐系统**:分析用户行为数据,提取与推荐相关的特征。
### Transformer架构
**作用**:Transformer架构是一种基于自注意力机制的深度学习模型,能够有效处理序列数据中的长距离依赖问题,同时支持高效的并行计算。
**能干什么**:通过多头自注意力机制和前馈网络,Transformer能够捕捉序列中各元素之间的复杂关联,适用于多种序列到序列的学习任务。
**一般拿来分析的问题**:
- **自然语言处理**:如机器翻译、文本生成、语言模型训练等。
- **时间序列分析**:处理具有时间依赖性的数据,如股票价格预测、天气预报等。
- **推荐系统**:基于用户行为序列进行个性化推荐。
- **生物信息学**:分析基因序列、蛋白质结构等。
在数学建模比赛中,注意力机制和Transformer架构可以根据具体问题的特点和数据类型进行选择和应用,以实现更好的建模效果。
注意力机制¶
注意力机制是一种模拟人类注意力的模型技术,它允许模型在处理序列数据时,动态地为每个位置分配不同的权重,从而捕捉序列中任意两个位置之间的依赖关系。这种机制在自然语言处理(NLP)中尤为重要,因为它可以帮助模型更好地理解句子中不同词语之间的关系。
Transformer架构¶
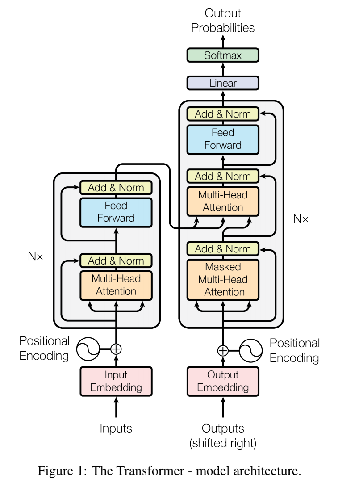
Transformer 是一种基于注意力机制的深度学习模型,最初由 Vaswani 等人在 2017 年的论文《Attention is All You Need》中提出。
它突破了传统序列模型(如 RNN 和 LSTM)的局限,能够并行处理序列数据,从而大大提高了训练效率和模型性能。
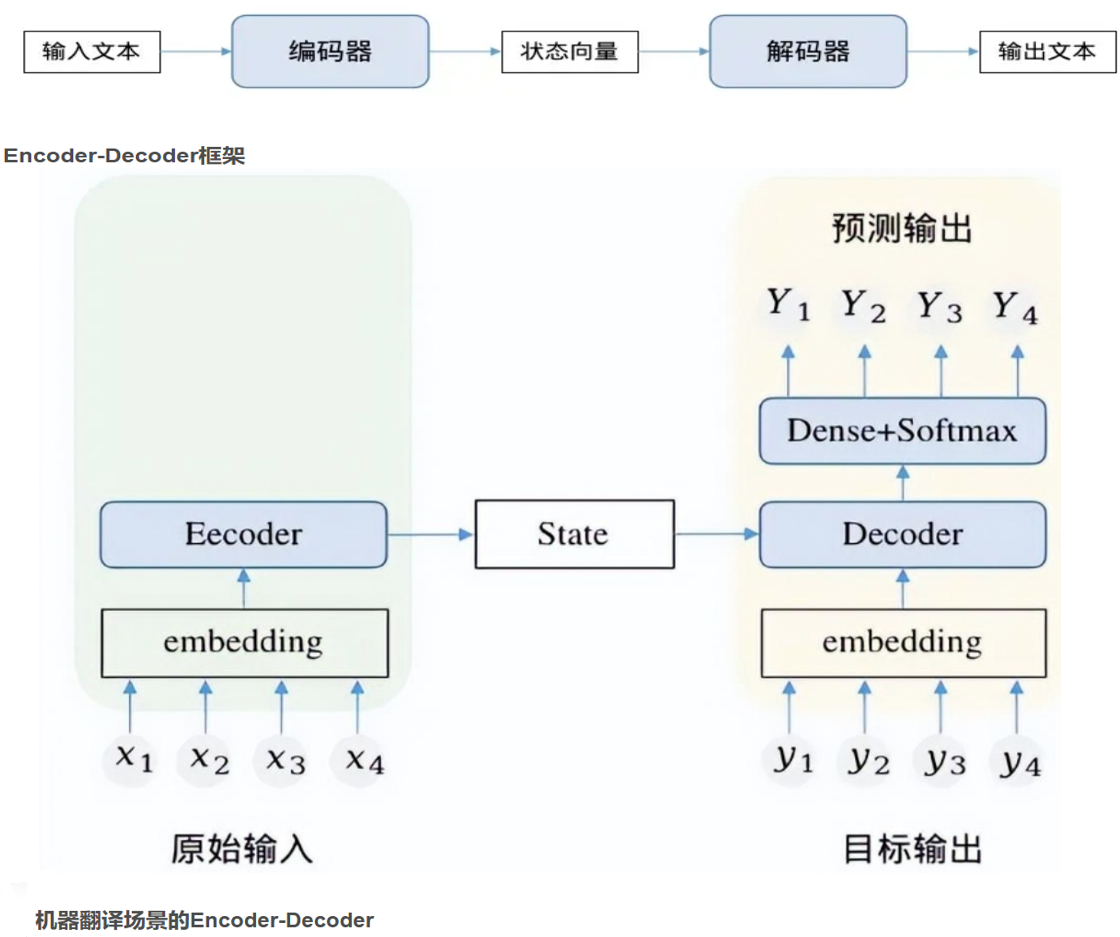
Transformer 模型由两个主要部分组成:编码器(Encoder)和解码器(Decoder)。
编码器 会对完整的输入句子通过各种复杂非线性变换生成State,代表原始输入被编码器编码之后形成的中间语义状态。编码器输出中间语义向量。
解码器 融合解码器语义和历史解码信息。是从第一个单词开始,逐位预测下一个单词,最终实现了从X翻译到Y的任务。
编码器(Encoder)¶
编码器的主要作用是将输入序列转换为一组上下文向量,供解码器使用。每个编码器层包括两个主要的子层:
- 多头自注意力机制(Multi-Head Self-Attention):捕捉输入序列中不同位置之间的依赖关系。通过不同的注意力头(Attention Heads),模型可以从多个不同的角度来看待输入序列。
- 前馈神经网络(Feed-Forward Neural Network, FFN):对经过注意力机制处理的序列进行进一步的非线性变换。
每个子层之后都会使用残差连接(Residual Connection)和层归一化(Layer Normalization),这有助于避免梯度消失问题并加快训练收敛速度。
解码器(Decoder)¶
解码器的结构与编码器类似,包含多个相同的层,但解码器的每一层有三个子层:
- 掩码自注意力层(Masked Multi-Head Attention):计算输出序列中每个词与前面词的相关性,使用掩码防止未来信息泄露。
- 编码器-解码器注意力层(Encoder-Decoder Attention):计算输出序列与输入序列的相关性。
- 前馈神经网络(Feed-Forward Neural Network, FFN):对每个词进行独立的非线性变换。
同样,每个子层后面都接有残差连接和层归一化。
Transformer模型算法¶
Transformer模型的算法主要包含以下几个步骤:
输入表示¶
输入文本首先需要转换为向量形式。通常,我们使用词嵌入(Word Embeddings)来表示每个单词。假设输入句子长度为 \(L\),词嵌入的维度为 \(d\),则输入可以表示为一个 \(L \times d\) 的矩阵。
位置编码¶
由于Transformer没有使用传统的RNN或CNN架构,因此需要添加位置编码来让模型获取序列信息。
位置编码通过将每个位置的信息编码为一个向量,并将其添加到对应的Token embedding上,使得模型能够区分不同位置的Token。
位置编码可以是固定的(如使用正弦和余弦函数生成的位置编码)或可学习的(Learned Positional Embedding),在原始的Transformer论文中,使用了正弦和余弦函数来生成位置编码,因为这种方法能够外推到训练期间未遇到的序列长度。
多头注意力机制¶
多头注意力机制是将输入分成多个头,每个头进行独立的注意力计算,然后将结果拼接起来并投影到输出空间。具体步骤如下:
- 计算查询、键和值矩阵:给定输入序列的表示 \(X\),我们计算三个矩阵:查询矩阵(Query)、键矩阵(Key)和值矩阵(Value)。这些矩阵通过输入与可训练的权重矩阵相乘得到。
- 计算注意力得分:注意力得分通过点积计算得到: $$ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V $$ 其中,\(d_k\) 是键矩阵的维度,点积得到的结果除以 \(\sqrt{d_k}\) 是为了防止数值过大引起的梯度消失问题。
- 分头计算:假设有 \(h\) 个头,每个头的维度为 \(d/h\)。每个头独立计算注意力。
- 拼接与线性变换:将所有头的输出拼接起来,并通过一个可训练的投影矩阵进行线性变换,得到最终的多头注意力输出。
前馈神经网络¶
每个注意力头的输出会通过一个前馈神经网络进行进一步处理。前馈神经网络由两个线性变换和一个 ReLU 激活函数组成:
其中,\(W_1\) 和 \(W_2\) 是权重矩阵,\(b_1\) 和 \(b_2\) 是偏置。
残差连接和层归一化¶
为了保持网络的稳定性和信息流动,Transformer 在每个子层之后使用残差连接和层归一化。具体来说,每个子层的输出是:
其中,\(\text{Sublayer}(x)\) 是子层的输出,\(\text{LayerNorm}\) 是层归一化操作。
总结¶
Transformer 模型通过引入自注意力机制和多头注意力机制,解决了传统序列模型的梯度消失和并行计算问题,显著提升了模型的性能和效率。其主要特点包括:
- 并行计算:能够同时处理整个输入序列,大大提高了训练效率。
- 长距离依赖捕捉:通过自注意力机制,能够有效地捕捉序列中任意两个位置之间的依赖关系。
- 灵活的应用场景:广泛应用于自然语言处理、计算机视觉等多个领域。
Transformer模型在自然语言处理任务中表现出色,能够高效处理长文本并生成高质量的文本输出。