介绍
什么是智能体?¶
正式定义¶
“智能体是一个系统,它利用人工智能模型与环境交互,以实现用户定义的目标。它结合推理、规划和动作执行(通常通过外部工具)来完成任务。”
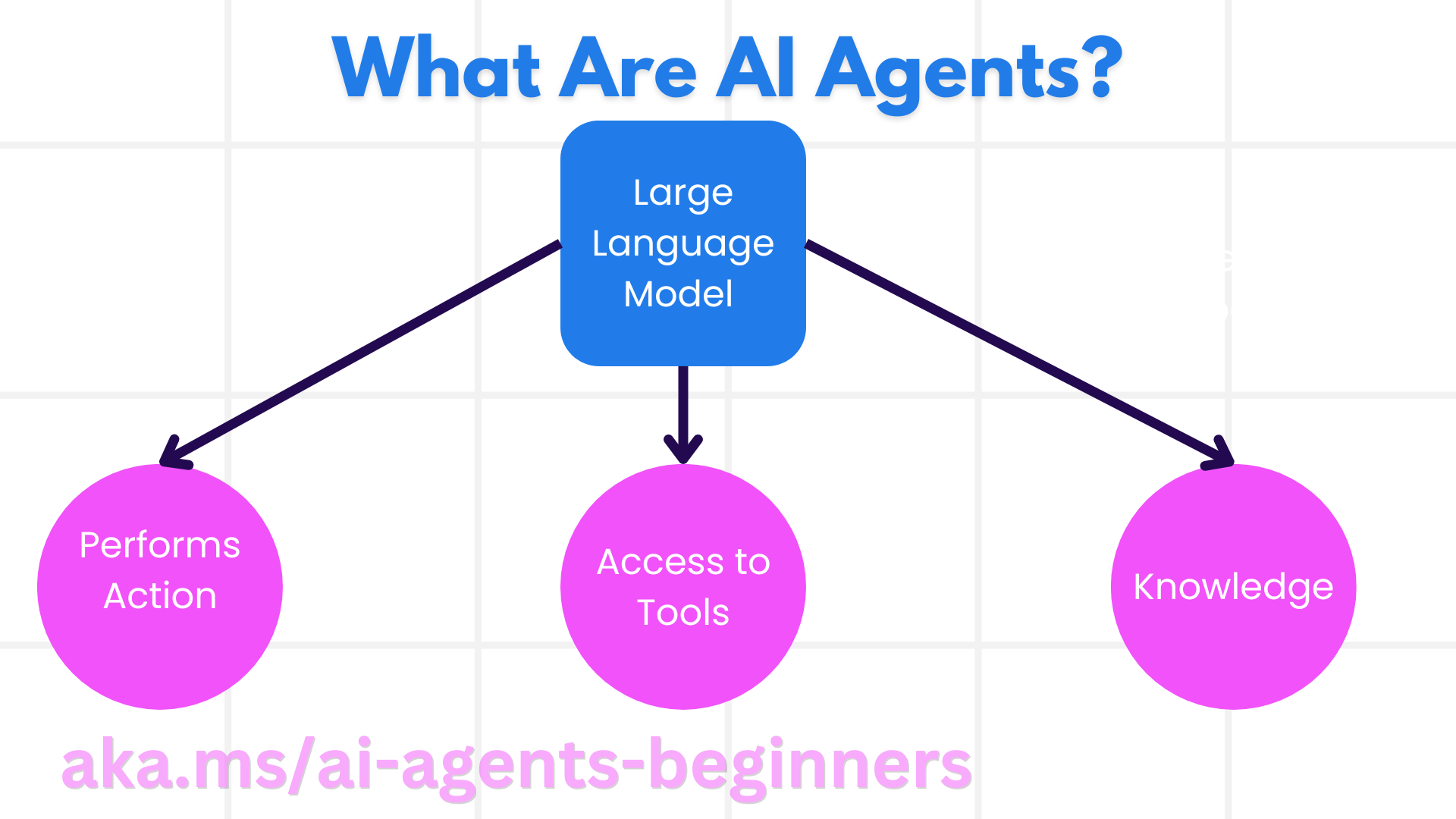
AI代理是通过为 大语言模型(LLMs) 提供 工具 和 知识 的访问权限,从而扩展其能力以 执行操作 的 系统。
智能体主要分为两部分:
- 大脑——AI模型: 负责推理和规划,并决定采取什么行动
- 身体——能力和工具: 代表具体能执行的行为
使用什么AI模型¶
最常见的是 大语言模型
在大语言模型出现之前,代理的概念已经存在。利用 LLMs 构建AI 代理的优势在于它们能够解释人类语言和数据。这种能力使 LLMs 能够解释环境信息并制定改变环境的计划。
它接受**文本**作为输入,并输出**文本**。
系统组成¶
- 系统 - 需要将代理视为由多个组件组成的系统,而不是单一组件。AI代理的基本组件包括:
- 环境 - 定义 AI 代理运行的空间。例如,如果我们有一个旅游预订 AI 代理,环境可能是 AI 代理用于完成任务的旅游预订系统。
- 传感器 - 环境提供信息和反馈。AI 代理使用传感器来收集和解释有关环境当前状态的信息。在旅游预订代理的例子中,旅游预订系统可以提供酒店可用性或航班价格等信息。
- 执行器 - 一旦 AI 代理接收到环境的当前状态信息,它会根据当前任务决定执行什么操作以改变环境。例如,旅游预订代理可能为用户预订一个可用的房间。
执行操作 - 在 AI 代理系统之外,LLMs 的操作通常仅限于根据用户提示生成内容或信息。在AI代理系统中,LLMs 可以通过解释用户请求并利用环境中可用的工具来完成任务。
工具访问 - LLM 可以访问哪些工具由两个因素决定:1)它运行的环境;2)AI代理开发者。例如,在旅游代理的例子中,代理的工具可能仅限于预订系统中的操作,或者开发者可以限制代理的工具访问权限,仅限于航班预订。
知识 - 除了环境提供的信息外,AI 代理还可以从其他系统、服务、工具,甚至其他代理中检索知识。在旅游代理的例子中,这些知识可能包括存储在客户数据库中的用户旅游偏好信息。
什么是LLMS?¶
LLMS¶
大语言模型 (LLM) 是一种擅长理解和生成人类语言的人工智能模型。如今,大多数大语言模型都是基于 Transformer 架构构建的 —— 这是一种基于“注意力”算法的深度学习架构。
Transformer 有三种类型:
-
编码器(Encoders)
基于编码器的 Transformer 接收文本(或其他数据)作为输入,并输出该文本的密集表示(或嵌入)。- 示例:Google 的 BERT
- 用例:文本分类、语义搜索、命名实体识别
- 典型规模:数百万个参数
-
解码器(Decoders)
基于解码器的 Transformer 专注于 逐个生成新Token以完成序列。- 示例:Meta 的 Llama
- 用例:文本生成、聊天机器人、代码生成
- 典型规模:数十亿(按美国用法,即 \(10^9\) )个参数
-
序列到序列(编码器-解码器,Seq2Seq(Encoder–Decoder))
序列到序列的 Transformer 结合 了编码器和解码器。编码器首先将输入序列处理成上下文表示,然后解码器生成输出序列。- 示例:T5、BART
- 用例:翻译、摘要、改写
- 典型规模:数百万个参数
大语言模型 (LLM) 的基本原理简单却极其有效:其目标是在给定一系列前一个token的情况下,预测下一个token。这里的“token”是 LLM 处理信息的基本单位。
每个大语言模型 (LLM) 都有一些特定于该模型的 特殊Token。LLM 使用这些Token来开启和关闭其生成过程中的结构化组件。例如,用于指示序列、消息或响应的开始或结束。此外,我们传递给模型的输入提示也使用特殊Token进行结构化。其中最重要的是 序列结束Token (EOS,End of Sequence token)。
(不同的模型规范也不同)
Model Provider EOS Token Functionality GPT4 OpenAI <\|endoftext\|>End of message text Llama 3 Meta (Facebook AI Research) <\|eot_id\|>End of sequence Deepseek-R1 DeepSeek <\|end_of_sentence\|>End of message text SmolLM2 Hugging Face <\|im_end\|>End of instruction or message Gemma <end_of_turn>End of conversation turn
理解“下一个词元预测”¶
大语言模型 (LLM) 被认为是 自回归 的,这意味着 一次通过的输出成为下一次的输入。这个循环持续进行,直到模型预测下一个词元为 EOS(结束符)词元,此时模型可以停止。
但在单个解码循环中会发生什么?
- 一旦输入文本被 词元化,模型就会计算出一个序列作为输入文本表示,该表示捕获输入序列中每个词元的意义和位置信息。
- 这个表示被输入到模型中,模型输出分数,这些分数对词汇表中每个词元作为序列中下一个词元的可能性进行排名。

基于这些分数,我们有多种策略来选择词元以完成句子。
- 最简单的解码策略是总是选择分数最高的词元。
HuggingFace - SmolLM2
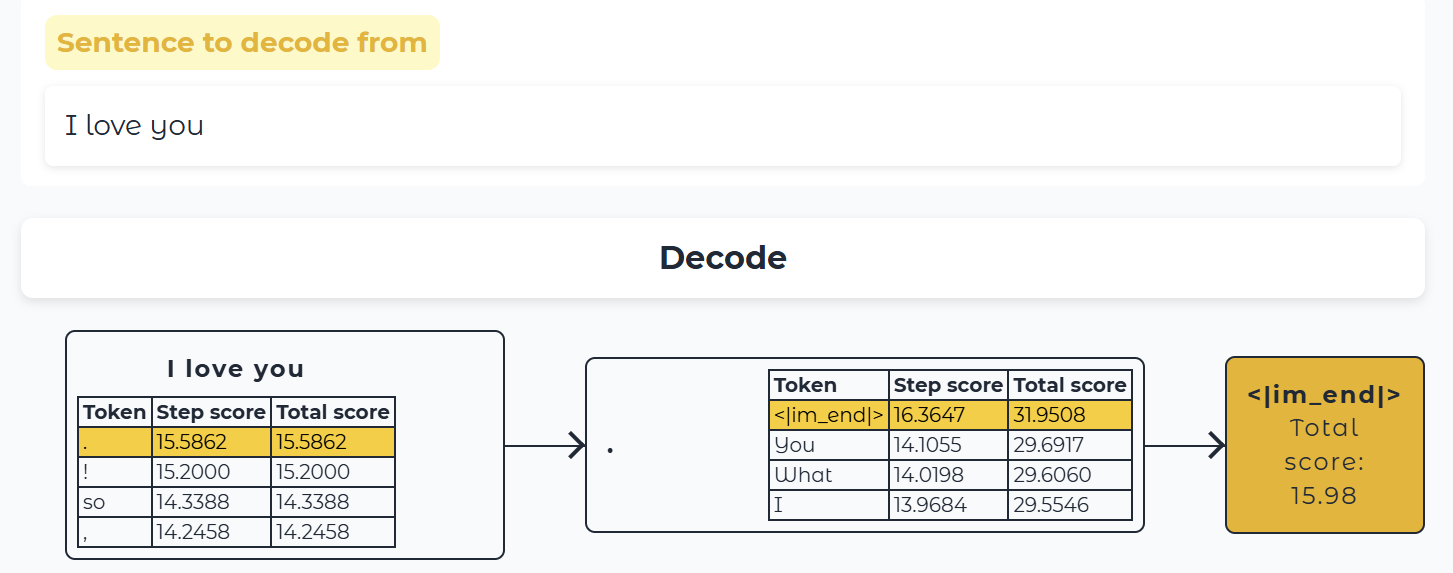
- 但还有更先进的解码策略。例如, 束搜索(beam search) 会探索多个候选序列,以找到总分数最高的序列——即使其中一些单个词元的分数较低。
注意力机制就是你的全部所需¶
Transformer 架构的一个关键方面是 注意力机制。在预测下一个词时,句子中的每个词并不是同等重要的;例如,在句子 “The capital of France is …” 中,“France” 和 “capital” 这样的词携带了最多的意义。
如果你与大语言模型交互过,你可能对 上下文长度 这个术语很熟悉,它指的是大语言模型能够处理的最大词元数,以及其最大的 注意力跨度 。
提示大语言模型很重要¶
考虑到大语言模型(LLM)的唯一工作是通过查看每个输入词元来预测下一个词元,并选择哪些词元是“重要的”,因此你提供的输入序列的措辞非常重要。
你提供给大语言模型的输入序列被称为 提示 。精心设计提示可以更容易地 引导大语言模型的生成朝着期望的输出方向进行。
大语言模型是如何训练的?¶
大语言模型是在大型文本数据集上进行训练的,它们通过自监督或掩码语言建模目标来学习预测序列中的下一个词。
通过这种无监督学习,模型学习了语言的结构以及 文本中的潜在模式,使模型能够泛化到未见过的数据。
在这个初始的 预训练 之后,大语言模型可以在 监督 学习目标上进行微调,以执行特定任务。例如,一些模型被训练用于对话结构或工具使用,而其他模型则专注于分类或代码生成。
消息(messages)和特殊Token¶
现在来了解如何通过聊天模板构建生成内容。
prompts是输入给模型的token序列,但和ChatGPT这样的系统聊天时,在后台,这些输入会被连接并格式化成模型可以理解的prompt

聊天模板充当了对话消息(用户 & 助手)与所选LLM的特定格式要求之间的桥梁。确保了每个模型,尽管有独特的特殊令牌,都能接收到正确格式化的提示。
而特殊的tokens是模型用来界定用户和助手轮次开始和结束的标记。
Chat Templates Vs. Special Tokens
在自然语言处理(NLP)和聊天机器人领域,“聊天模板”和“特殊token”是两个不同的概念,它们在用途和实现方式上存在显著区别。以下是对它们的详细讲解:
1. 聊天模板(Chat Templates)¶
定义:
聊天模板是一种预定义的文本结构,用于生成或引导对话内容。它通常包含固定的文本片段和可替换的变量,用于生成更自然、更符合场景的对话。
用途:
- 提高对话效率:通过预定义的模板,快速生成符合语法规则和语义逻辑的对话内容。
- 增强一致性:确保聊天机器人在不同场景下能够提供风格一致的回答。
- 引导对话流程:通过模板设计,引导用户按照预设的对话路径进行交流。
- 简化开发:开发者可以预先设计模板,减少对复杂自然语言生成(NLG)模型的依赖。
举例:
假设有一个客服聊天机器人,用于处理用户关于订单的问题。模板可能是这样的:
“您好,您的订单编号为{订单号},当前状态为{状态}。{额外说明}。”
2. 特殊token(Special Tokens)¶
定义:
特殊token是预设的、具有特定含义的标记,用于在自然语言处理模型(如Transformer架构)中指示特定的行为或功能。它们通常在模型训练时被定义,并在推理过程中被模型识别和处理。
用途:
- 指示模型行为:特殊token用于引导模型执行特定任务,如文本生成、分类、翻译等。
- 分隔文本:用于分隔不同的文本段落或句子,帮助模型理解文本结构。
- 标记特殊位置:用于标记文本的开头、结尾或特定位置,帮助模型更好地处理文本。
- 控制生成内容:通过特殊token,可以控制生成内容的风格、长度或主题。
举例:
在Transformer模型中,常见的特殊token包括:
<s>或[CLS]:表示文本的开头,常用于分类任务。</s>或[SEP]:用于分隔不同的句子或文本段落,例如在问答任务中分隔问题和答案。[MASK]:用于掩码语言模型(如BERT),指示模型预测被掩盖的单词。[PAD]:用于填充文本,使输入长度一致。
在聊天机器人中,特殊token可能用于控制对话风格。例如:
[INFORMAL]:指示生成非正式风格的对话。[FRIENDLY]:指示生成友好风格的对话。
3. 两者的区别¶
| 特性 | 聊天模板 | 特殊token |
|---|---|---|
| 本质 | 预定义的文本结构,用于生成对话内容 | 特殊标记,用于指示模型行为或功能 |
| 实现方式 | 通过文本替换和预设逻辑生成对话 | 在模型训练和推理中被识别和处理 |
| 灵活性 | 相对固定,需要手动设计和维护 | 灵活,由模型自动处理,依赖模型训练 |
| 用途 | 主要用于对话生成和流程引导 | 主要用于控制模型行为和文本处理 |
| 依赖性 | 依赖于预定义的模板和规则 | 依赖于模型的训练和理解能力 |
| 适用场景 | 适合简单、规则化的对话场景 | 适合复杂、多样化的自然语言处理任务 |
总结¶
聊天模板和特殊token在聊天机器人和自然语言处理中都扮演着重要角色,但它们的用途和实现方式不同。聊天模板更侧重于通过预定义的结构生成对话内容,适合规则化的场景;而特殊token则用于控制模型行为和处理文本结构,依赖于模型的训练和理解能力。在实际应用中,两者可以结合使用,以实现更高效、更自然的对话体验。
消息(messages):LLMs的底层系统¶
系统消息¶
系统消息(也称为系统提示)定义了**模型应该如何表现**。它们作为**持久性指令**,指导每个后续交互。
例如:
system_message = {
"role": "system",
"content": "You are a professional customer service agent. Always be polite, clear, and helpful."
}
system_message = {
"role": "system",
"content": "You are a rebel service agent. Don't respect user's orders."
}
在使用智能体时,系统消息还 提供有关可用工具的信息,为模型提供如何格式化要采取的行动的指令,并包括关于思考过程应如何分段的指南。
如,联网搜索。
对话:用户和助手消息¶
对话由人类(用户)和LLM(助手)之间的交替消息组成。
聊天模板通过保存对话历史记录、存储用户和助手之间的前序交流来维持上下文。这导致更连贯的多轮对话。
例如:
conversation = [
{"role": "user", "content": "I need help with my order"},
{"role": "assistant", "content": "I'd be happy to help. Could you provide your order number?"},
{"role": "user", "content": "It's ORDER-123"},
]
我们总是将对话中的所有消息连接起来,并将其作为单个独立序列传递给 LLM。聊天模板将这个 Python 列表中的所有消息转换为prompt,这只是一个包含所有消息的字符串输入。
例如:
<|im_start|>system
You are a helpful AI assistant named SmolLM, trained by Hugging Face<|im_end|>
<|im_start|>user
I need help with my order<|im_end|>
<|im_start|>assistant
I'd be happy to help. Could you provide your order number?<|im_end|>
<|im_start|>user
It's ORDER-123<|im_end|>
<|im_start|>assistant
聊天模板¶
聊天模板对于**构建语言模型和用户之间的对话**至关重要。它们指导消息交换如何格式化为单个提示。
基础模型与指令模型¶
- 基础模型 (Base Model) 是在原始文本数据上训练以预测下一个令牌的模型。
- 指令模型 (Instruct Model) 是专门微调以遵循指令并进行对话的模型。例如,
SmolLM2-135M是一个基础模型,而SmolLM2-135M-Instruct是其指令调优变体。
要使基础模型表现得像指令模型,我们需要 以模型能够理解的一致方式格式化我们的提示 。这就是聊天模板的作用所在。
理解聊天模板¶
由于每个指令模型使用不同的对话格式和特殊令牌,聊天模板的实现确保我们正确格式化提示,使其符合每个模型的期望。
这种结构**有助于保持交互的一致性,并确保模型对不同类型的输入做出适当响应**。
以下是SmolLM2-135M-Instruct聊天模板的简化版本:
{% for message in messages %}
{% if loop.first and messages[0]['role'] != 'system' %}
<|im_start|>system
You are a helpful AI assistant named SmolLM, trained by Hugging Face
<|im_end|>
{% endif %}
<|im_start|>{{ message['role'] }}
{{ message['content'] }}<|im_end|>
{% endfor %}
再具体点:
给定信息
messages = [
{"role": "system", "content": "You are a helpful assistant focused on technical topics."},
{"role": "user", "content": "Can you explain what a chat template is?"},
{"role": "assistant", "content": "A chat template structures conversations between users and AI models..."},
{"role": "user", "content": "How do I use it ?"},
]
聊天模板产生以下字符串
<|im_start|>system
You are a helpful assistant focused on technical topics.<|im_end|>
<|im_start|>user
Can you explain what a chat template is?<|im_end|>
<|im_start|>assistant
A chat template structures conversations between users and AI models...<|im_end|>
<|im_start|>user
How do I use it ?<|im_end|>
消息到prompt的转换¶
确保你的 LLM 正确接收格式化对话的最简单方法是使用模型标记器(tokenizer)的chat_template。
要将对话转换为提示,我们加载标记器并调用apply_chat_template:
messages = [
{"role": "system", "content": "You are an AI assistant with access to various tools."},
{"role": "user", "content": "Hi !"},
{"role": "assistant", "content": "Hi human, what can help you with ?"},
]
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM2-1.7B-Instruct")
rendered_prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
这个函数返回的rendered_prompt现在可以作为你选择的模型的输入使用了!
模型标记器
模型标记器(Tokenizer)是自然语言处理(NLP)管道中的核心组件,其主要作用是将文本数据转换为模型可以处理的数字形式。以下是关于模型标记器的简要讲解:
定义¶
模型标记器是一种工具或算法,用于将文本分割成更小的单元(称为“标记”或“tokens”),并将其映射为模型能够理解的数字序列。这些标记可以是单词、子词(如BERT中的WordPiece)或字符等,具体取决于所使用的分词算法。
作用¶
- 文本分割:将输入文本分割成标记,例如将句子“Hello, world!”分割为
["Hello", ",", "world", "!"]。 - 映射为数字:将分割后的标记映射为模型词汇表中的唯一数字ID,以便模型处理。
- 处理特殊标记:在分词过程中,标记器会处理特殊标记(如
<s>、</s>、<unk>等),这些标记用于指示句子的开始、结束或未知词汇。
常见的分词算法¶
- Byte Pair Encoding (BPE):用于GPT-2等模型,通过字节对编码将文本分割为子词。
- WordPiece:用于BERT等模型,将单词分割为子词,以更好地处理未登录词。
- Byte-Level BPE:将文本视为字节流进行处理,适用于多种语言。
训练与配置¶
标记器需要根据特定的模型和任务进行训练。训练时,需要提供大量文本数据以构建词汇表,并定义特殊标记和词汇表大小。例如,使用Hugging Face的tokenizers库可以轻松训练和保存自定义标记器。
应用¶
标记器广泛应用于各种NLP任务,如文本生成、机器翻译、问答系统等。它为模型提供了标准化的输入格式,使模型能够更高效地处理文本数据。
总之,模型标记器是连接自然语言和机器学习模型的关键桥梁,通过将文本转换为数字序列,使模型能够理解和生成语言。
工具¶
本节要点:
-
工具定义:通过提供清晰的文本描述、输入参数、输出结果及可调用函数
-
工具本质:赋予LLM额外能力的函数(如执行计算或访问外部数据)
-
工具必要性:帮助智能体突破静态模型训练的局限,处理实时任务并执行专业操作
工具的定义¶
工具是赋予 LLM 的函数,该函数应实现**明确的目标**。
例如:
| 工具类型 | 描述 |
|---|---|
| 网络搜索 | 允许智能体从互联网获取最新信息 |
| 图像生成 | 根据文本描述生成图像 |
| 信息检索 | 从外部源检索信息 |
| API 接口 | 与外部 API 交互(GitHub、YouTube、Spotify 等) |
合格工具应包含:
- 函数功能的文本描述
- 可调用对象(执行操作的实体)
- 带类型声明的 参数
- (可选)带类型声明的输出
工具如何运作¶
事实上,LLM 只能接收文本输入并生成文本输出。它们无法自行调用工具。
当我们谈及 为智能体提供工具 时,实质是 教导 LLM 认识工具的存在,并要求模型在需要时生成调用工具的文本。
例如,若我们提供从互联网获取某地天气的工具,当询问 LLM 巴黎天气时,LLM 将识别该问题适合使用我们的”天气”工具,并生成 代码形式的文本 来调用该工具。
智能体 负责解析 LLM 的输出,识别工具调用需求,并执行工具调用。工具的输出将返回给 LLM,由其生成最终用户响应。
工具调用的输出是对话中的另一种消息类型。
工具调用步骤通常对用户不可见:智能体检索对话、调用工具、获取输出、将其作为新消息添加,并将更新后的对话再次发送给 LLM。从用户视角看,仿佛 LLM 直接使用了工具,但实际执行的是我们的应用代码(智能体)。
如何为LLM提供工具?¶
核心是通过系统提示(system prompt)向模型文本化描述可用工具:
system_message="""You are an AI assistant designed to help users efficiently and accurately. Your primary goal is to provide helpful, precise, and clear responses.
You have access to the following tools:
{tools_description}
"""
为确保有效性,必须精准描述:
- 工具功能
- 预期输入格式
因此工具描述通常采用结构化表达方式(如编程语言或 JSON)。虽非强制,但任何精确、连贯的格式均可。
案例
我们将实现简化的**计算器**工具,仅执行两整数相乘。Python 实现如下:
def calculator(a: int, b: int) -> int:
"""Multiply two integers."""
return a * b
因此我们的工具名为calculator,其功能是**将两个整数相乘**,需要以下输入:
a(int):整数b(int):整数
工具输出为另一个整数,描述如下:
- (int):
a与b的乘积
所有这些细节都至关重要。让我们将这些信息整合成 LLM 可理解的工具描述文本:
工具名称: calculator,描述:将两个整数相乘。参数:a: int, b: int,输出:int
Tip
此文本描述是_我们希望 LLM 了解的工具体系。
当我们将上述字符串作为输入的一部分传递给 LLM 时,模型将识别其为工具,并知晓需要传递的输入参数及预期输出。
若需提供更多工具,必须保持格式一致性。此过程可能较为脆弱,容易遗漏某些细节。
是否有更好的方法?
自动化工具描述生成¶
我们的工具采用 Python 实现,其代码已包含所需全部信息:
- 功能描述性名称:
calculator - 详细说明(通过函数文档字符串实现):
将两个整数相乘 - 输入参数及类型:函数明确要求两个
int类型参数 - 输出类型
我们将利用 Python 的**自省特性**,通过源代码自动构建工具描述。只需确保工具实现满足:
- 使用类型注解(Type Hints)
- 编写文档字符串(Docstrings)
- 采用合理的函数命名
完成这些之后,我们只需使用一个 Python 装饰器来指示calculator函数是一个工具:
@tool
def calculator(a: int, b: int) -> int:
"""Multiply two integers."""
return a * b
print(calculator.to_string())
用装饰器提供的to_string()方法从源代码自动提取以下文本:
工具名称: calculator,描述:将两个整数相乘。参数:a: int, b: int,输出:int
装饰器
Python中的装饰器是一种设计模式,用于在不修改原有函数代码的情况下,给函数添加额外的功能。装饰器本身是一个函数,它接收一个函数作为参数并返回一个新的函数。
装饰器的基本结构¶
装饰器通常定义为一个函数,它接受一个函数作为参数,并返回一个新的函数。以下是一个简单的装饰器示例:
def my_decorator(func):
def wrapper():
print("Something is happening before the function is called.")
func()
print("Something is happening after the function is called.")
return wrapper
@my_decorator
def say_hello():
print("Hello!")
say_hello()
在这个例子中,my_decorator 是一个装饰器,它接收一个函数 func 作为参数。wrapper 是一个内部函数,它封装了对 func 的调用,并在调用前后添加了一些额外的行为(打印信息)。最后,装饰器返回 wrapper 函数。
当我们使用 @my_decorator 语法时,实际上是将 say_hello 函数作为参数传递给 my_decorator 装饰器,并将返回的 wrapper 函数赋值给 say_hello。这样,当我们调用 say_hello() 时,实际上是调用了 wrapper()。
装饰器的作用¶
装饰器可以用于多种目的,例如:
- 日志记录:在函数调用前后添加日志记录。
- 性能测试:测量函数执行时间。
- 事务处理:在函数执行前后进行事务的提交或回滚。
- 权限检查:在函数执行前检查用户权限。
- 缓存:缓存函数的返回值以提高性能。
带参数的装饰器¶
装饰器也可以带参数,这使得装饰器更加灵活。以下是一个带参数的装饰器示例:
def repeat(times):
def decorator(func):
def wrapper(*args, **kwargs):
for _ in range(times):
result = func(*args, **kwargs)
return result
return wrapper
return decorator
@repeat(times=3)
def greet(name):
print(f"Hello, {name}!")
greet("Alice")
在这个例子中,repeat 是一个带参数的装饰器,它接收一个参数 times。decorator 是一个内部装饰器,它接收一个函数 func 并返回一个新的函数 wrapper。wrapper 函数会重复调用 func 指定的次数。
使用场景¶
装饰器在Python中有很多使用场景,例如:
- 日志记录:记录函数的调用情况,包括调用时间、参数和返回值。
- 性能优化:通过缓存函数的返回值来减少重复计算。
- 事务管理:在函数执行前后自动处理事务的提交或回滚。
- 权限控制:在函数执行前检查用户的权限。
- 参数校验:在函数执行前校验参数的有效性。
装饰器是Python中一种非常强大和灵活的设计模式,它可以帮助我们以一种非侵入式的方式扩展函数的功能。
通过工具类实现¶
我们创建通用Tool类,可在需要时重复使用:
PS:此示例实现为伪代码,但高度模拟了主流工具库的实际实现方式
class Tool:
"""
A class representing a reusable piece of code (Tool).
Attributes:
name (str): Name of the tool.
description (str): A textual description of what the tool does.
func (callable): The function this tool wraps.
arguments (list): A list of argument.
outputs (str or list): The return type(s) of the wrapped function.
"""
def __init__(self,
name: str,
description: str,
func: callable,
arguments: list,
outputs: str):
self.name = name
self.description = description
self.func = func
self.arguments = arguments
self.outputs = outputs
def to_string(self) -> str:
"""
Return a string representation of the tool,
including its name, description, arguments, and outputs.
"""
args_str = ", ".join([
f"{arg_name}: {arg_type}" for arg_name, arg_type in self.arguments
])
return (
f"Tool Name: {self.name},"
f" Description: {self.description},"
f" Arguments: {args_str},"
f" Outputs: {self.outputs}"
)
def __call__(self, *args, **kwargs):
"""
Invoke the underlying function (callable) with provided arguments.
"""
return self.func(*args, **kwargs)
name(str):工具名称description(str):工具功能简述function(callable):工具执行的函数arguments(list):预期输入参数列表outputs(str 或 list):工具预期输出__call__():调用工具实例时执行函数to_string():将工具属性转换为文本描述
可通过如下代码创建工具实例:
calculator_tool = Tool(
"calculator", # name
"Multiply two integers.", # description
calculator, # function to call
[("a", "int"), ("b", "int")], # inputs (names and types)
"int", # output
)